The render lane and the grep lane
HTML for my eyes, Markdown for my machines — and the layer I was missing between my files and my head.
Forty markdown files in one project, and I'd lost the system they belonged to. Each one read fine on its own; together they were a machine I could only understand by re-reading the whole thing, every time I came back to it.
Around then a post from Anthropic went around — the unreasonable effectiveness of HTML — with Karpathy boosting the one-line version: append structure your response as HTML and read what comes back as a page. I agreed on sight. For my eyes, HTML beats Markdown. But the whole argument was about the next thing the agent makes, and my problem was the forty files already sitting there.
The author, Thariq, is honest about what HTML actually buys you:
The real reason I use HTML instead of Markdown is that it helps me feel much more in the loop with Claude. You stay in the loop, but the loop gets much tighter.
That loop is about generation — the next answer, rendered nicer. Mine ran the other way. The project had grown to 19 skills and roughly 80,000 tokens of markdown. Every file was readable on its own. The system was not.
Here's the part I kept circling. 80,000 tokens isn't a time limit, it's a cognitive bandwidth limit: working memory holds maybe five to seven conceptual blocks at once. One skill in one HTML file isn't a description of the system. It's a description of a node in a graph where the graph itself is drawn nowhere. Switching to a nicer format doesn't fix that after the fact. Prettier files are still forty files.
So I stopped thinking about format and started thinking about lanes. Two of them, and they won't merge.
---
name: mdhumanviewer
description: "mdHumanViewer: assemble one self-contained, strongly
human-readable HTML overview from a group of related Markdown files
(skills, specs, RCA notes, docs) so a human grasps a whole system in
minutes instead of reading dozens of files. View, not storage: reads
existing .md without modifying them; output is regenerated on demand.
Read-once and fully parallel: each source enters an LLM context exactly
twice (render + verify), both as N parallel agents in one turn ..."
---
# mdHumanViewer
Read a group of Markdown files and assemble from them a single
self-contained HTML representation, optimized for human perception of the
system **as a whole**. The design follows the project manifesto's
render-lane / grep-lane split over a disk-as-contract backbone, with two
hard rules: each source `.md` is read into an LLM context **exactly
twice** (render + verify), **both fully parallel**, and there are **zero
serial whole-corpus generation passes**.
## Operating principles (read before running)
- **View, not storage.** Never edit the source `.md`. Every run is a fresh
full regeneration into a new dated session directory under
`<ROOT>/.mdHumanViewer/`.
- **Disk is the contract between stages.** `structure.json` →
`fragments/<slug>.html` + `analysis/<slug>.json` →
`findings.json` → `overview.html`. Each stage reads from disk and
writes to disk.
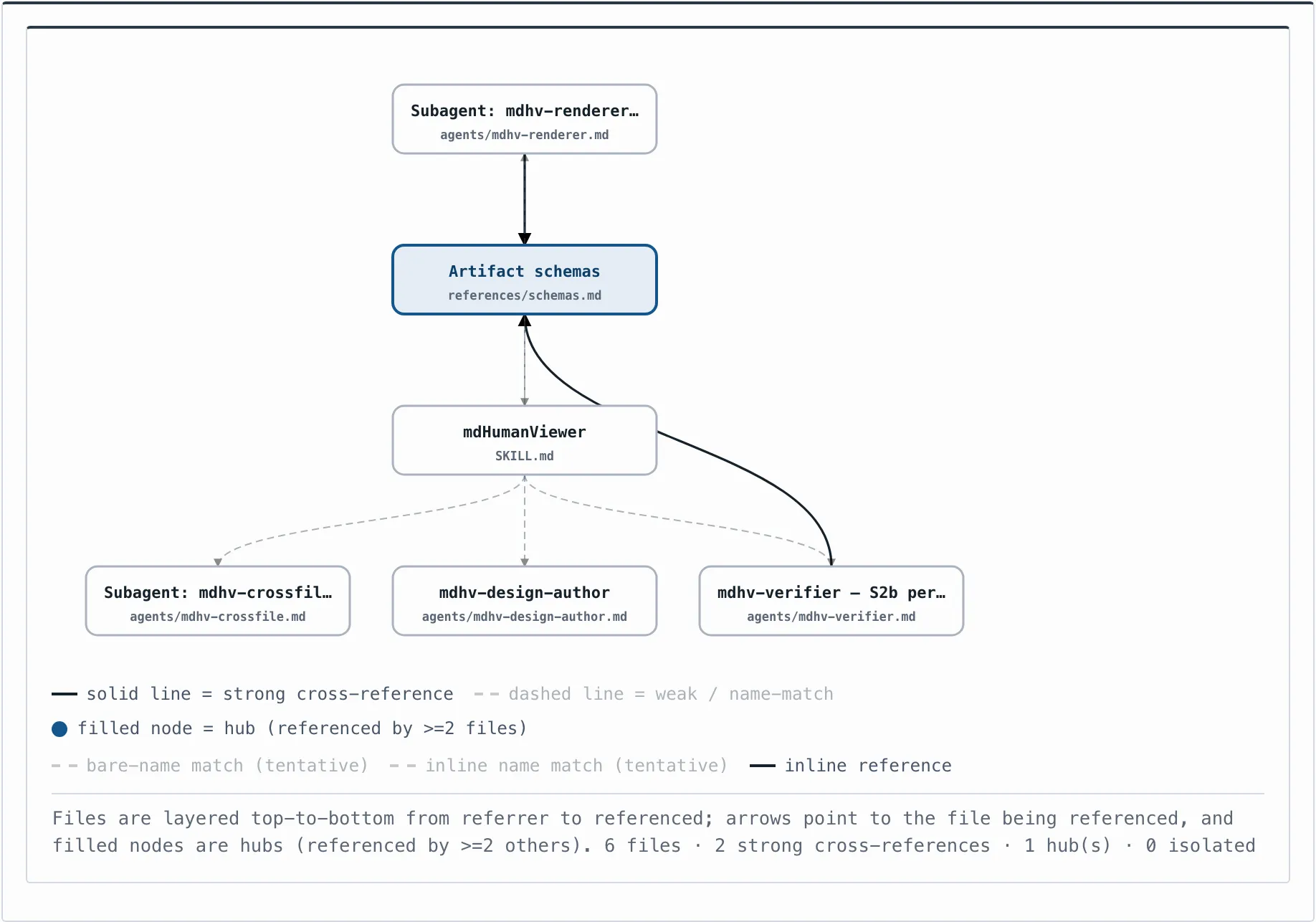
The grep lane is Markdown. It diffs, it takes a regex, it composes incrementally, an agent parses it cheaply. That's the substrate — where the files live and where the machines work. None of it wants to be HTML.
The render lane is HTML, and it has one job: be looked at by a human. Generated on demand, for my eyes, then thrown away. The principle that made it click was view, not storage. The view doesn't have to be saved. Markdown stays the substrate; HTML appears when I need to see the whole thing at once, and disappears when I'm done. Neither lane does the other's job.
I wrote it down before I built anything — a gist, mostly to argue with myself and check the idea survived contact with plain prose. The line I kept: the render lane and the grep lane won't merge. Then I built it into a Claude Code plugin.

A view like this only earns trust if it's cheap and doesn't lie — otherwise it's worse than the forty files. So the rules are strict. Each file is read exactly twice: once to render it, once to check the render. Both passes run in parallel, so the cost tracks the biggest file, not the whole pile. Everything else — finding the files, drawing the graph, assembling the page — is plain Python, not the model. And nothing ships if the page quietly drops something the source actually said: a few checks fail the build instead.
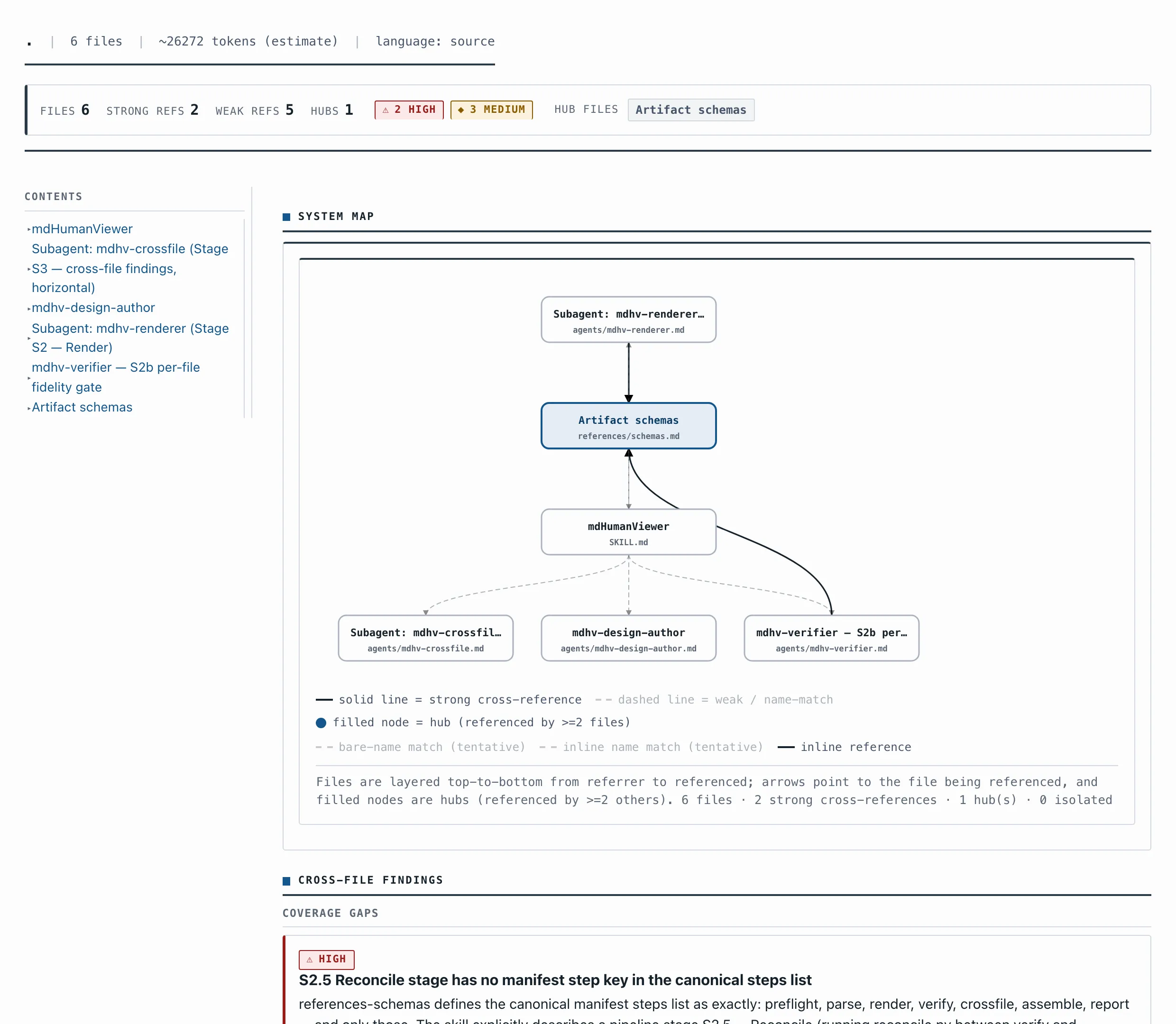
The honest test was to point it at its own documentation. Six files — the skill, four agent specs, the schema reference — about 26k tokens. Small enough that I figured I knew them. I didn't.
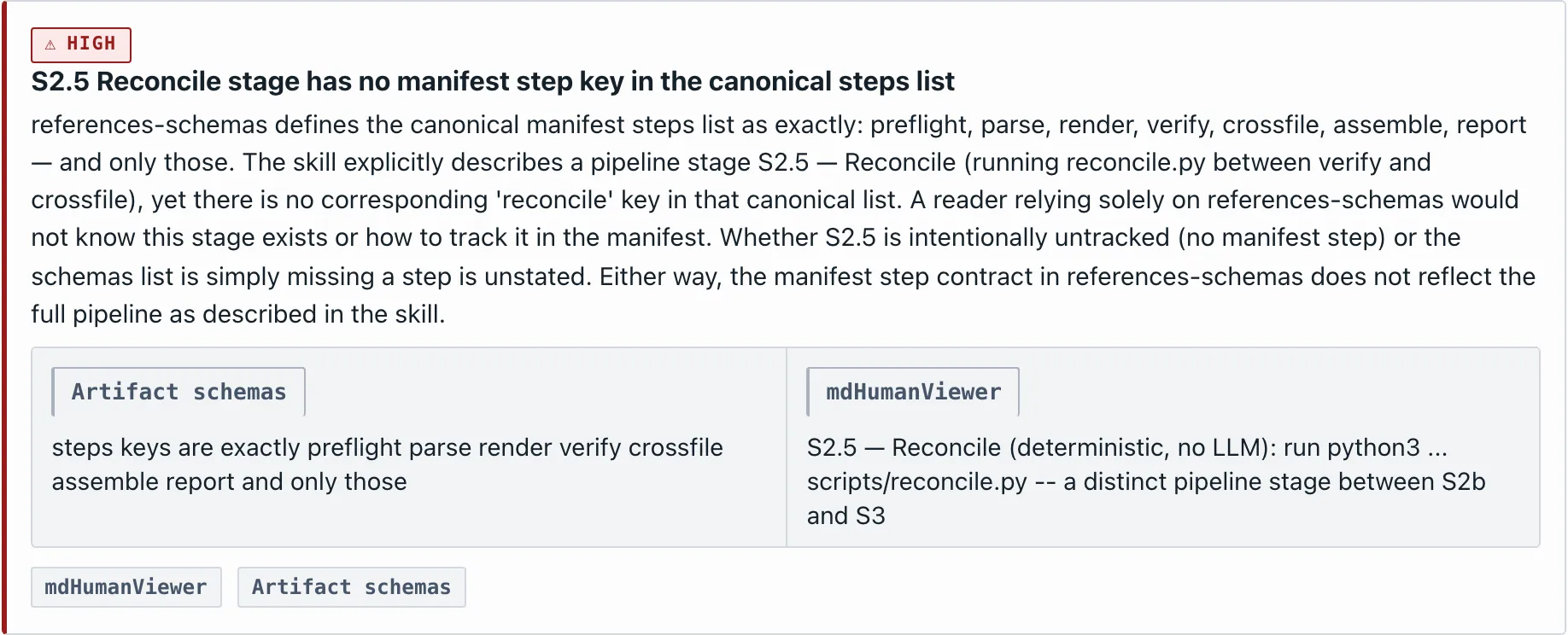
It flagged a contradiction in my own docs, high severity. One file — the skill — describes a pipeline stage called S2.5 Reconcile. Another file — the schema reference — lists the pipeline's steps, and that stage isn't on the list. Read only the schema, and it doesn't exist. I wrote both files. I'd read both. I never caught it, because the two were never in front of me at once. The contradiction lived in the gap between two files — the one place no single file can show you.
What changed is smaller and more useful than I expected. Coming back to that project used to mean re-reading forty files; now it's one overview, in a couple of minutes. It isn't a change log — git already does that — it's a map of what's actually there. And every so often it catches something I'd never have found in any single file.
The loop did get tighter, the way the original post promised. Only mine didn't tighten around the next thing the agent would generate — it tightened around everything I'd already written and could no longer hold in my head. That was the gap I'd been trying to close.
Markdown isn't going anywhere. HTML appears when it's needed. And neither of them lays claim to exclusivity.